Garbage collections on Tomcat provoke timeout exceedings on Apache

Author: king
Publication Date: 9/2/2014 8:56
Dear e-Spirit community,
we just observe in the productive Tomcat instances:
- a heavy usage of the survivor space within the new generation
- a weak usage of the old generation
of the Oracle JVM. It seems, that the deployed and running FirstSpirit web applications there create short-living Java objects heavily that just reside in the:
- eden (1 GB)
- survivor (from / to: 1GB each)
spaces of the new generation. The old generation stays nearly untouched and unused. Below a screenshot of the JConsole for a tomcat instance in the productive environment:
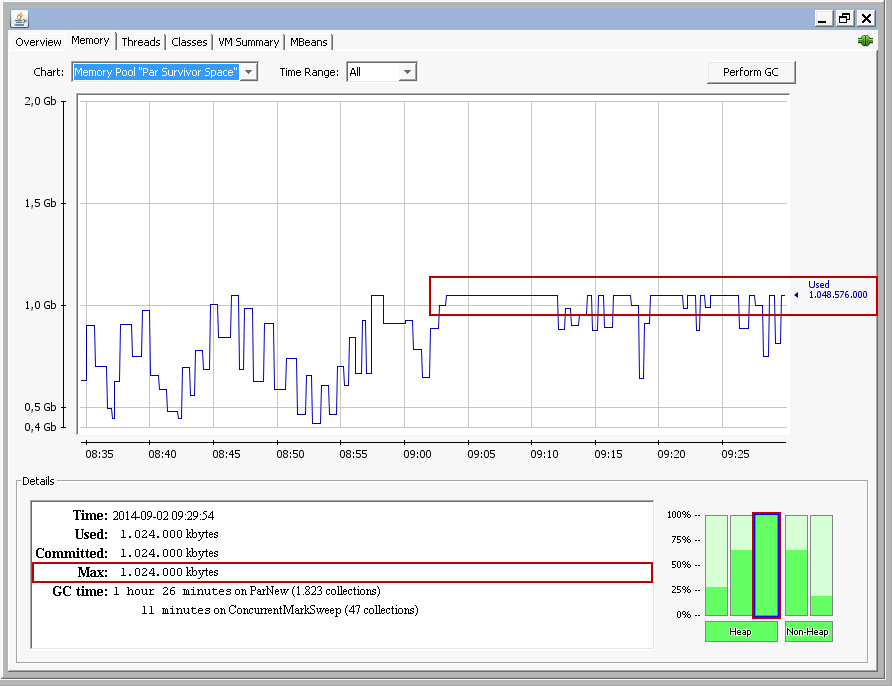
The current JVM configuration looks like:
-Xmx10000m \
-Xms10000m \
-Xmn3000m \
-XX:PermSize=170m \
-XX:MaxPermSize=512m \
-XX:+DisableExplicitGC \
-Djava.awt.headless=true \
-d64 \
-verbose:gc \
-XX:+PrintGCTimeStamps \
-XX:+PrintGCDateStamps \
-XX:+PrintGCDetails \
-XX:+PrintGCApplicationStoppedTime \
-XX:+PrintTenuringDistribution \
-XX:+UseParNewGC \
-XX:+UseConcMarkSweepGC \
-XX:+CMSParallelRemarkEnabled \
-XX:+CMSClassUnloadingEnabled \
-XX:+CMSIncrementalMode \
-XX:SurvivorRatio=1 \
-XX:TargetSurvivorRatio=80 \
-XX:InitialTenuringThreshold=5 \
-XX:MaxTenuringThreshold=10 \
-XX:-UseLargePages \
-XX:SoftRefLRUPolicyMSPerMB=20 \
-XX:+UseBiasedLocking \
-XX:ParallelGCThreads=7 \
-XX:+HeapDumpOnOutOfMemoryError
When taking a closer look on the GC log output enriched via "PrintTenuringDistribution" we see:
- the majority of objects (counted in bytes) survive just 5 GC runs in the survivor space
Desired survivor size 838860800 bytes, new threshold 10 (max 10)
- age 1: 149813296 bytes, 149813296 total
- age 2: 150828560 bytes, 300641856 total
- age 3: 74822664 bytes, 375464520 total
- age 4: 116746640 bytes, 492211160 total
- age 5: 152362528 bytes, 644573688 total
- age 6: 45243968 bytes, 689817656 total
- age 7: 8149584 bytes, 697967240 total
- age 8: 14459600 bytes, 712426840 total
- age 9: 7236896 bytes, 719663736 total
- age 10: 30650336 bytes, 750314072 total
It seems, that too many blocking GCs on Tomcat side lead to the following error message on Apache side when having configured a PING timeout of 5s on Apache side in module "mod_proxy_ajp":
[Tue Sep 02 09:24:11.475890 2014] [proxy_ajp:error] [pid 25964:tid 33] (70007)The timeout specified has expired: AH01030: ajp_ilink_receive() can't receive header
Hint: the above timeout error message does occur whenever a configured timeout threshold in Apache for:
- timeout (reply timeout)
- ping (CPING/CPONG timeout)
exceeded (threshold exceedings of the "connectiontimeout" attribute do not provoke the above Apache error message!). Either by a GC or a long running request that could not be replied within the timeout value. Here, we focus on (2).
The assumption is that a blocking GC on Tomcat side provoked the PING error:
Total time for which application threads were stopped: 12.1258575 seconds
As Apache does currently not log PING requests, we cannot look how long the ping really took and compare the values with the GC duration :smileysad:
Do you have any suggestions to improve that behaviour on a Oracle JVM 6 update 81 environment to allow a CPING connection check being done in 5s and not being disturbed by a blocking GC?
- increasing the new space to reduce GC runs in the eden by setting "Xmn" to "5000m"
- increasing the eden to survivor ratio by increasing the "SurvivorRatio" setting to 2 (eden double the size of survivor from and to)
We are looking forward to heading from you.
Tags: java, oracle
-
Author: Peter_Jodeleit - 9/2/2014 13:24
In which phase of the GC the pause occurs? Is it really a 12 second "stop the world" pause?
Does Oracle Java 6u81 uses compressed ops by default? If not, did you already tried this?
0 -
Author: king - 9/2/2014 15:05
Dear Peter,
we suppose you think of the JVM configuration directive:
- XX:+UseCompressedOopsas we use a 64bit JVM. Correct? The problem: starting with Java 6u23 it seems to be activated by default according to this web page respectively a page created by Oracle directly. So, the question is, whether we should really explicitly set it?
Regarding your first question, we see:
2014-09-02T09:10:13.763+0200: 248098.974: [GC[YG occupancy: 1189037 K (2048000 K)]2014-09-02T09:10:13.763+0200: 248098.975: [Rescan (parallel) , 5.6090719 secs]2014-09-02T09:10:19.373+0200: 248104.584: [weak refs processing, 5.3681923 secs]2014-09-02T09:10:24.741+0200: 248109.953: [class unloading, 0.1829213 secs]2014-09-02T09:10:24.924+0200: 248110.136: [scrub symbol & string tables, 0.0415524 secs] [1 CMS-remark: 2856086K(7168000K)] 4045123K(9216000K), 12.1134059 secs] [Times: user=36.92 sys=0.29, real=12.11 secs]
Total time for which application threads were stopped: 12.1258575 seconds
2014-09-02T09:10:25.877+0200: 248111.089: [CMS-concurrent-sweep-start]
Total time for which application threads were stopped: 0.0237557 seconds
Total time for which application threads were stopped: 0.0128559 seconds
To our understanding, the 12s pause happens in a JVM GC phase where it provokes a "stop the world" run. Do you agree?
- What about our suggestions of tuning above?
- are there more ideas on your side?
0 -
Author: Peter_Jodeleit - 9/3/2014 11:26
Yes, "UseCompressedOps" was the switch I had in mind. It won't hurt to set it explictly..
Now to your log: "CMS-remark: 2856086K(7168000K)] 4045123K(9216000K), 12.1134059 secs".
CMS-remark isn't performed in parallel (description of this phase is "Stop-the-world phase. This phase rescans any residual updated objects in CMS heap, retraces from the roots and also processes Reference objects."). There is no "doing this to speed up this phase" advice possible, it's always a bit of trial and error sadly. That said, I would try to adjust the ratio between the eden and the survior spaces. The time should increases when young gen is larger and decrease when the size of the young gen is reduced.
[EDIT]
It's a bit old, but perhaps you can get some tips from here: http://mail.openjdk.java.net/pipermail/hotspot-gc-use/2008-September/000205.html
0 -
Author: isenberg - 9/8/2014 15:30
As the application creates many temporary objects, reducing -XX:SoftRefLRUPolicyMSPerMB=20 to 1 would decrease the number of those objects if some of the objects are soft/weak references. In addition I suggest increasing the -Xmn value as long as the NewGen GC pauses stay below an acceptable pause limit, maybe about 0.5s. Generally, using the OldGen space for short lived temporary objects should be avoided as using the OldGen for temporary objects creates fragmentation and thereby Full GC after longer runtime. The current problem is the 12s pause caused by the CMS GC, as Peter already mentioned. CMS GC is the selected implementation for the OldGen GC. It is the best choice for FirstSpirit, but in this case overloaded.
Maybe removing -XX:+CMSIncrementalMode helps, as that is an optimization for systems with 4 or less CPU cores.
To even increase the usage of NewGen and reducing the load on the OldGen (CMS-GC) replace-XX:TargetSurvivorRatio=80
-XX:InitialTenuringThreshold=5
-XX:MaxTenuringThreshold=10
with
-XX:+NeverTenure
Then objects from NewGen are kept as long NewGen is not completely filled, only then they are promoted to OldGen to create space for new objects in NewGen.
The only drawback of a large NewGen is its high RAM usage as it requires 2 - 3 times the Java objects's size amount of RAM with the mirrored survivor spaces.
To be sure, which parameter change really improves the situation, please test each change one after the other. All parameter suggestions, except for the Xmn increase are current standard values of FirstSpirit 5.0.
0 -
Author: king - 9/9/2014 7:56
Interesting note regarding the "NeverTenure" option. According to the following web page this JVM directive might mean that objects located in "New" are never promoted to "Old" where the CMS collector runs.
But according to H. Isenberg and his observations "never" is not really the case. As soon as one of the two survivor spaces is completely filled up with referenced objects and new objects are waiting for a move in "NewGen", the oldest objects will be moved to "OldGen". Without having configured "NeverTenure" these objects would have been moved at a certain age - independent of the filling state. The disadvantage: really long living objects are copied unnecessary long. But when the ratio between temporary/long living is permanent very big, as when using FirstSpirit, this does not attract attention.
Starting with Oracle Java 1.8.0_40 e-Spirit hopes to use the G1 collector for FirstSpirit in productive environments as a full GC for the PermGen/MetaSpace will be dispensable then. When using FirstSpirit integrating reflection at a high level for its WebApp/JavaClient-Server-communication, the "PermGen" is occupied.
0 -
Author: isenberg - 9/9/2014 8:23
The definition of "NeverTenure" indeed seems to be ambiguous. We introduced this parameter around FirstSpirit 5.0 as standard in fs-wrapper.conf with Oracle Java 1.6.0_27 after seeing good results from automatic stress tests with FirstSpirit. The usage of OldGen heap space of a FirstSpirit server appears normal, even now with Oracle Java 1.7.0_67 with most of the OldGen used by the Berkeley cache.
This correlates with the following descriptions of this parameter:
http://blog.ragozin.info/2011/09/hotspot-jvm-garbage-collection-options.html
-XX:+NeverTenure
Objects from young space will never get promoted to tenured space while survivor space is large enough to keep them.
Though the lead developer of the CMS GC has a different opionion in the following URL, but gives no reason. My guess is, that there are good use cases for the parameter as shown with our automatic tests and there are other cases where the automatic tenuring method gives better results:
http://www.oracle.com/technetwork/server-storage/ts-4887-159080.pdf
-XX:+NeverTenure
● Very bad idea!
0
Please sign in to leave a comment.
Comments
6 comments